Official website
Mohamad Zamini builds efficient multimodal AI systems
Machine learning engineer and final-year PhD candidate focused on multimodal reasoning, large language model efficiency, and research-to-production AI systems.
About
Research depth with an engineering mindset.
I am a Computer Science PhD candidate at the University of Wyoming researching how to improve the efficiency and reasoning ability of multimodal large language models. My work combines causal reasoning, pruning, sparse attention, and architecture-level optimization to make advanced models more practical under real compute constraints.
I enjoy translating ambitious research ideas into systems people can actually use. That includes training and fine-tuning foundation models, building analytics and experimentation pipelines, and shaping ML workflows that are both scalable and interpretable.
I am especially interested in applied research and ML engineering roles where I can contribute to high-impact AI products, efficient model design, and rigorous experimentation.
Foundation model efficiency
Pruning, sparse attention, dynamic context selection, and routing strategies for faster inference.
Product-oriented AI systems
Analytics agents, session-level behavioral pipelines, and deployment-aware machine learning workflows.
Multimodal model reliability
Research on token-efficient multimodal architectures, hallucination reduction, and segmentation-aware vision-language systems.
Experience
Selected roles across research, product, and applied machine learning.

Microsoft
Data Science Intern
- Built an LLM-powered analytics agent for natural-language querying and multi-turn reasoning over large telemetry datasets.
- Automated weekly retention and engagement monitoring with SHAP, ANOVA, and anomaly-aware delta detection.
- Designed scalable data pipelines for session-level behavioral modeling and experimentation.
Python
PyTorch
Telemetry analytics
Numenta
Machine Learning Engineer Intern
- Fine-tuned Mistral and LLaMA models using activation sparsity and attention sparsity for efficient inference.
- Developed dynamic context pruning, kWTA mechanisms, and KV-cache optimizations to reduce compute overhead.
- Worked close to the model stack, experimentation loop, and inference performance tradeoffs.
PyTorch
Accelerate
LLM inference optimization

Teverra
Digital Innovation Intern
- Designed a semantic compression system using deep autoencoders for high-dimensional scientific data.
- Built machine learning models for geothermal data analysis and improved predictive accuracy through algorithmic tuning.
Deep learning
Scientific data
Optimization

Lifeweb
NLP Engineer Co-op
- Fine-tuned BART for Persian text summarization in a production-oriented NLP setting.
- Built sequence tagging pipelines with BiLSTM-CRF and topic modeling workflows using matrix factorization.
- Delivered practical NLP systems for multilingual and domain-specific text understanding.
Python
NLP
Sequence modeling
Projects
Hands-on work spanning interpretability, generative models, and multimodal systems.
Investor Lab
LLM app
Finance workflow
Built an investor-focused application that explores AI-assisted workflows for analyzing market and company information.
View repository
Delta-LLaVA
Multimodal AI
LLaVA
Extended multimodal modeling workflows around LLaVA-style systems, with an emphasis on efficient adaptation and practical experimentation.
View repository
Mafia-LLM-Arena
LLM agents
Social deduction
Explores LLM behavior in a Mafia-style arena where agents interact, reason, and adapt inside a social deduction game setting.
View repository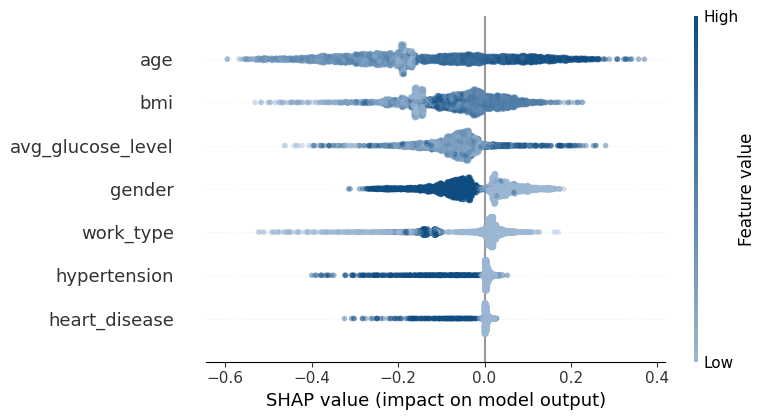
Explainability Analysis
SHAP
LIME
ELI5
Compared popular interpretability methods to understand feature importance and model behavior in a healthcare prediction workflow.
View repository
Causal Inference with Bayesian Networks
Causal reasoning
Bayesian networks
Explored causal structure and intervention-aware analysis for decision support and more robust ML reasoning.
View repository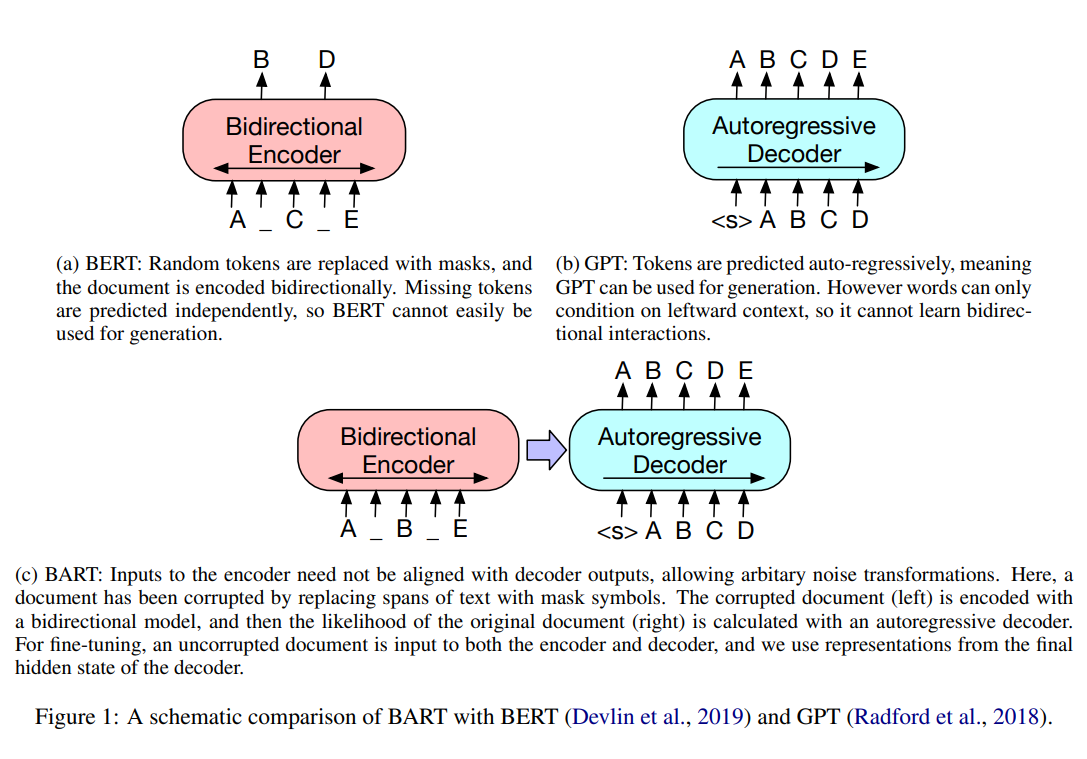
Bidirectional Autoregressive Transformers From Scratch
PyTorch
Transformers
Implemented the tokenizer, training loop, and transformer components from the ground up to study the full modeling stack.
View repository
Image Captioning with ViT and GPT-2
Vision transformer
GPT-2
Built a multimodal captioning pipeline that pairs visual representations with generative language modeling.
View repository
Attention-Based Graph Neural Network
Text classification
GNN
Developed a graph-attention approach for multi-label text classification to capture richer label and feature relationships.
View repository
GPT-2 for Python Code Assistance
Fine-tuning
Q&A
Fine-tuned GPT-2 into a lightweight Python question-answering assistant to explore code-focused generative behavior.
View repositorySkills
A toolkit shaped by research rigor and shipping real systems.
Languages and core ML
Python
C++
PyTorch
TensorFlow
Hugging Face
NumPy
Pandas
Optimization and deployment
Pruning
ONNX
TensorRT
TorchServe
FastAPI
Docker
Kubernetes
Data and infrastructure
PostgreSQL
MySQL
MongoDB
AWS
GCP
Azure
Git
Analysis and experimentation
Model interpretability
SHAP
ANOVA
OpenCV
Weights & Biases
NLTK
Education
Academic foundation in machine learning, reasoning, and advanced computation.
University of Wyoming
Degree: PhD in Computer Science
Research: Token-efficient multimodal architectures, hallucination reduction, and segmentation-aware vision-language modeling
Relevant coursework: Machine Learning, High Performance Computing, Advanced Image Processing, Neural and Fuzzy Systems, Artificial Intelligence
Tarbiat Modares University
Degree: Master of Information Technology
GPA: 3.68 / 4.0
Relevant coursework: Artificial Neural Networks, Neural and Fuzzy Systems
Contact
Open to ambitious work in applied AI, multimodal systems, and model optimization.
If you are hiring for machine learning engineering, research engineering, or foundation model work, I would be glad to connect.